RAG Precision Tuning: A Hidden Risk for AI Pipelines
New research reveals that fine-tuning RAG embedding models can reduce retrieval accuracy by up to 40%. Discover how this impacts enterprise AI pipelines and what it means for your data strategies.
The Hidden Dangers of Fine-Tuning RAG Models
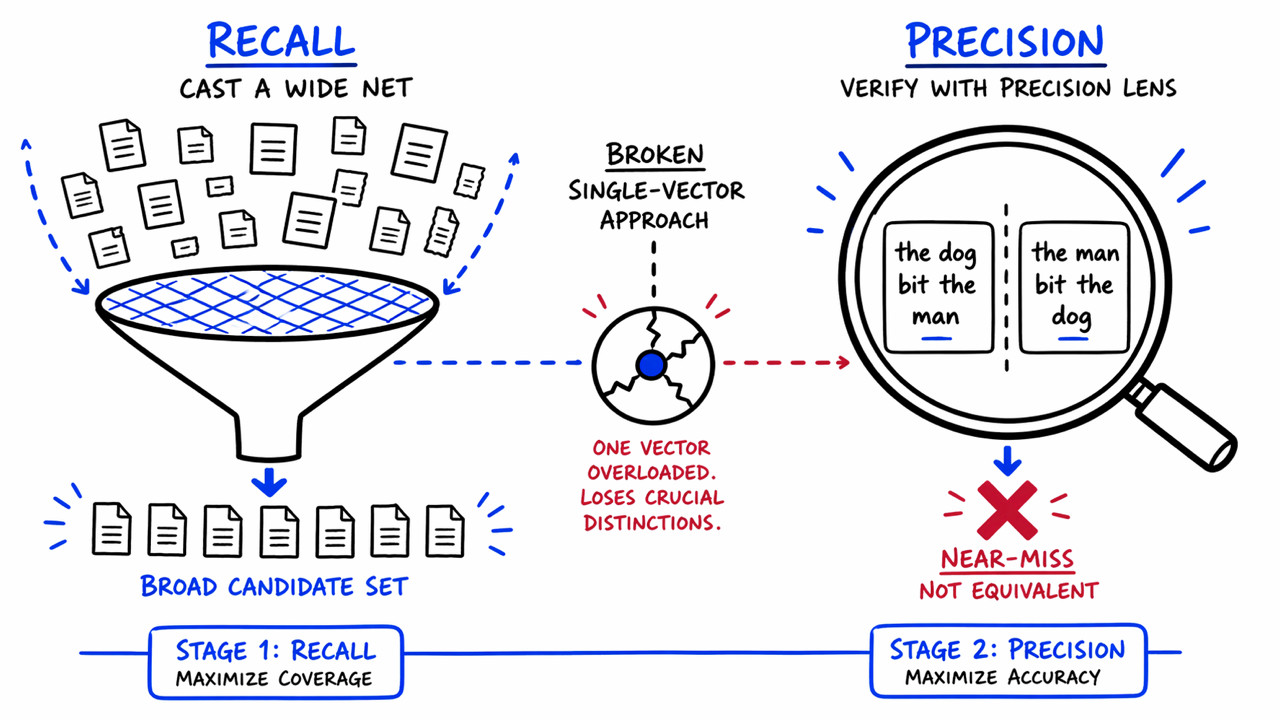
Enterprise teams often fine-tune their Retrieval-Augmented Generation (RAG) embedding models to enhance precision. However, a recent study from Redis indicates that this practice may inadvertently degrade retrieval quality, which is crucial for effective AI pipelines. The research highlights that training for compositional sensitivity—understanding nuanced sentence meanings—can lead to significant drops in performance, with mid-size models experiencing a staggering 40% decline.
The implications are profound for businesses relying on agentic AI systems. A single retrieval error can cascade into a series of incorrect actions, jeopardizing decision-making processes. As Srijith Rajamohan, AI Research Leader at Redis, points out, the assumption that high semantic similarity guarantees correct intent is misleading. This finding challenges the foundational understanding of how embedding-based retrieval operates, emphasizing the need for a more nuanced approach to model training.
- •Key Findings:
- •Fine-tuning can reduce retrieval accuracy by 8-40%.
- •Misinterpretation of sentence structure leads to errors.
- •Precision issues can have cascading effects in AI pipelines.
Understanding these risks is essential for teams looking to optimize their AI strategies without compromising on retrieval quality.